Vyčištění HTML knihy
O problematice převodu papírové knihy do e-booku ve formátu HTML už jsem na větší nebo menší úrovni abstraktnosti psal několikrát, v článku HTML jako e-bookový formát, v sérii článků Z papíru do čtečky (zejména v jeho páté části, Technická korektura) a naposledy v Šablona pro e-knihu v HTML. Nyní se v reakci na několik žádostí k tomuto tématu opět vracím, tentokrát se zcela konkrétním příkladem postupu: vyjdu z naskenovaných obrázků stránek, které proženu OCR programem FineReader do HTML souboru a na tomto souboru předvedu techniky, které používám k získání pěkného čistého HTML. Stav dokumentu po každém kroku, včetně samotyných naskenovaných obrázků, nabízím ke stažení, takže si to zájemci mohou sami vyzkoušet. Předem ale upozorňuji, že nejde o činnost pro lidi se slabými nervy.
Důležitá upozornění
Cílem tohoto článku je předvést maximálně konkrétně, jaký postup se mi osvědčil při převodu papírových knih do e-booků ve formátu HTML, a to v takovém HTML, které se mi líbí (viz šablona). Neřeším vůbec, že existují i nějaké jiné formáty, nebo že někomu jinému se líbí jiné HTML. Nezabývám se tím problémem, že z každého OCR programu vypadne trochu – nebo i hodně – jiný výstup, který se bude zpracovávat odlišně – klidně i zásadně odlišně. Počítejte s tím, že i když budete používat stále jeden OCR program, vyprodukuje pro každou knihu trochu jiný soubor; dokonce jsem si ověřil, že když stejnému programu předložím stejný vstup, jen zkonvertovaný do jiného formátu, nedostanu vždy stejný výstup. To, že uu všech kroků popisuji i myšlenky, na kterých je ten krok založen, není dáno tím, že jsem placen od slova (protože nejsem placen vůbec), ale tím, že docela jistě budete muset jednotlivé kroky tu méně, tu více modifikovat podle toho, jak vypadají vaše data.
Případně podle toho, jak se třeba i se stejnými daty vypořádávají různé programy. Speciálně regulární výrazy v tomto ohledu dělávají potíže – sice je podporuje každý druhý program, ale ještě jsem nenarazil na dva programy, které by používaly stoprocentně kompatibilní implementaci. Moje příklady jsou psané na použití ve FAR Manageru s pluginem Regular Expression Search and Replace ve verzi 6.20; můžete se spolehnout, že v jiných programech bude třeba jednotlivé výrazy poupravit. Pro ostatní editaci pak používám známý PSPad.
Rád bych ještě zdůraznil jednu věc: Neočekávejte, že aplikováním těchto postupů dostanete dokonalou knihu. Nejenže se v této fázi vůbec nedívám na chyby OCR (špatně rozpoznaná slova apod.), ale dokonce se ani nesnažím o absolutní správnost výsledného kódu. Všechno, co je popsáno dále v článku, slouží jen k tomu, abych hromadně opravil nejběžnější technické nedostatky, ale dopředu vím, že zůstanou některé chyby a dokonce vzniknou i nové; je nezbytné následně v knize za pomoci Validátoru odstranit nedostatky v kódu – a pak knihu důkladně přečíst a opravit i všechny ostatní chyby (a podotýkám, na odstranění všech nestačí, když knihu jednou přečte jeden člověk).
Pozn.: Pokud není uvedeno jinak, jsou všechny regulární výrazy prováděny s příznakem case-insensitive (nezáleží na velikosti písmenek) a všechny ostatní příznaky (multiline, dot-all, ungreedy atd.) jsou vypnuté (což je jejich výchozí hodnota).
Vstupy
Pro demonstraci celého procesu jsem si vybral část knížky The Unspeakable People – hlavním důvodem bylo to, že to je jediný materiál, který mám k dispozici, kterému už propadla ochrana autorského zákona; snad by bylo vhodnější použít nějakou českou knížku kvůli srozumitelnosti obsahu, ale jednak žádnou vhodnou nemám, a za druhé, v tomto článku konec konců nejde o ten vlastní obsah, ale o to, jak ho dostat do vhodné podoby. Použité postupy se, po vhodné úpravě, dají použít na všechny HTML zdroje. Pro úplnost dodávám, že soubory, se kterými pracuji, nejsou přesnou kopií originálu – mimo jiné jsem odstranil všechny části, které jsou dosud chráněným autorským dílem.
Pokud se chcete na konverzi podívat od úplného začátku, stáhněte si naskenované stránky ve formátu JPEG (můžete i ty samé ve formátu PNG, ale pozor na to, že se zOCRují na trochu jiný výstup) a nechte je programem FineReader 9.0 Professional převést do HTML v nastavení „Formátovaný text“; jedinou nestandardní volbou, kterou jsem použil, bylo „Použít plnou čáru jako zalomení strany“. Ostatní mohou začít až souborem, který na mě z FineReaderu vypadl: Dokument po OCR.
Odříznutí hlaviček
První věc, kterou ve svých převodech dělám, je likvidace hlavičky souboru. Důvodem je to, že stejně celou strukturu souboru podstatně překopu, použiji vlastní pojmenování stylů, a nakonec na soubor nasadím svoji vlastní hlavičku. Prakticky to znamená, že si najdu počátek vlastního textu knihy, a všechno před ním smažu. U této konkrétní knihy to znamená smazat všechno až po <body> včetně:
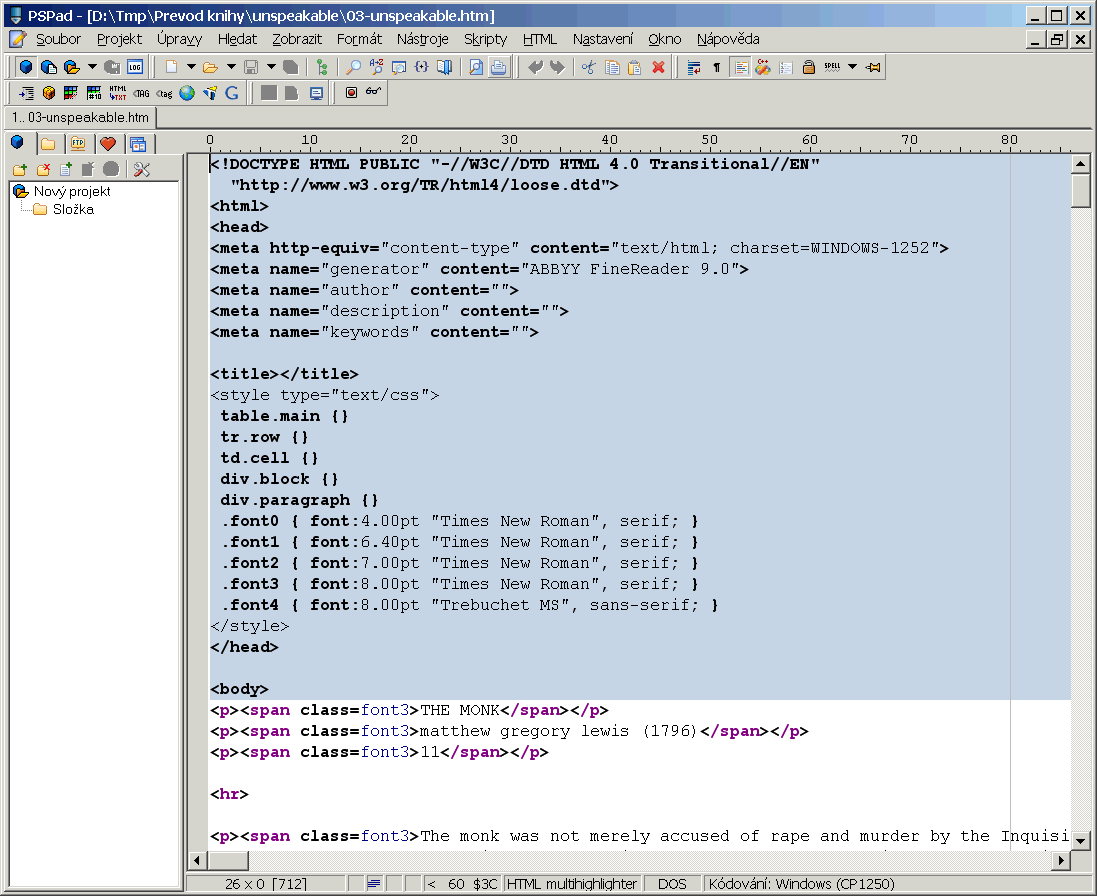
Soubor knihy po tomto kroku: Download.
Vyčištění odstavců
Hned poté, co jsem se zbavil hlaviček, se pouštím do základního vyčištění odstavců – tím mám na mysli to, že drtivou většinu textu chci mít v podobě:
<p>První odstavec</p> <p>Druhý odstavec</p>
Z OCR programu ovšem leze něco podstatně složitějšího, v případě FineReaderu 9.0 vesměs něco jako:
<p><span class=font3>První odstavec</span></p> <p><span class=font3>Druhý odstavec</span></p>
Řešení je poměrně jednoduché: Pohled do souboru odhalí standardní tvar běžného textu, v našem případě tedy to, co vidíte kousek nahoře: odstavec začíná na <p><span class=font3>, pak následuje vlastní text, a za ním se nachází zakončení </span></p>. Celý text odstavce je přitom až na výjimky uložen v jediném řádku, což situaci podstatně zjednodušuje. (Pozn.: Kdyby tomu tak nebylo, musel bych vymyslet nějaký způsob, jak napřed text přeformátovat. Existuje několik cest, jak to udělat, ale ty si nechám do nějakého budoucího článku – bude se to hodit v popisu, jak udělat pěkné HTML z DOCu.) Opravu lze udělat jednoduchým regulárním výrazem: do pole „najít“ zkopíruji libovolný odstavec, ve kterém ale místo vlastního textu odstavce napíšu (.*) (=libovolný znak, libovolněkrát opakovaný) – tedy v tomto případě <p><span class=font3>(.*)</span></p>. Jediný problém by nastal, kdyby v definici odstavce byl některý z řídících znaků regulárních výrazů – ten by pak bylo potřeba nahradit, obvykle tečkou. Do pole „nahradit“ pak dávám vždy stejný text: <p>$1</p> (= napřed <p>, potom obsah první nalezené závorky, tedy vlastní text odstavce, a nakonec </p>). Spustím nahrazování a drtivá většina textu by se měla opravit.
Pozn.: Pokud se ve formálních jazycích trochu vyznáte, nebo pokud máte zkušenosti aspoň s HTML a regulárními výrazy, asi vás napadlo, že tohle nahrazení může docela snadno vést k syntakticky nesprávnému výsledku. Ano, může. Ale to pro tuto chvíli není podstatné, to mohu vyřešit až v závěrečné fázi, kdy se snažím zpracovaný dokument protlačit validátorem.
Soubor knihy po tomto kroku: Download.
Hlavičky a patičky
Dalším krokem je odstranění standardních hlaviček a patiček – je celkem běžné, že kniha má na každé stránce v hlavičce svůj název nebo jméno autora a v patičce číslo stránky. Ani jedno z toho v e-booku nechci. Otázka ovšem je, jak to odstranit. Nejjednodušší je případ, který shodou okolností nastal zrovna v této knize, že kniha má pouze číslování stránek, ale žádnou jinou hlavičku ani patičku. Mohu využít postup z vyčištění odstavců a nahradit odstavce čísel prázdným řetězcem. „Najít“ bude odvozeno z celého řádku s číslem stránky, jen místo původního čísla bude [0-9]+ (=sekvence číslic) – v našem případě <p>[0-9]+</p> a „Nahradit“ bude prázdné.
Co dělat s případnými záhlavími? Teoreticky by se měly dát odstranit obdobným postupem, praktickou zkušenost mám ale takovou, že to téměř nikdy nejde – nevím proč, ale speciálně v záhlavích si OCR vymýšlejí nejrůznější podivné znaky, takže jen tak jednoduše něco nahradit nejde. Experimentoval jsem svého času s prográmkem, který z naskenovaných obrázků to záhlaví automaticky odstraní, dokonce jsem se dostal k celkem přijatelným výsledkům, ale nakonec jsem přešel k manuálnímu způsobu, který se mi osvědčil jako méně pracný: Procházím postupně dokumentem, na každé stránce označím blok od konce předchozí stránky do začátku následující stránky a klávesou DELETE smažu; tím poměrně rychle odstraním jak čísla stránek, tak všechna záhlaví a ještě přitom může spojit odstavce podle potřeby:
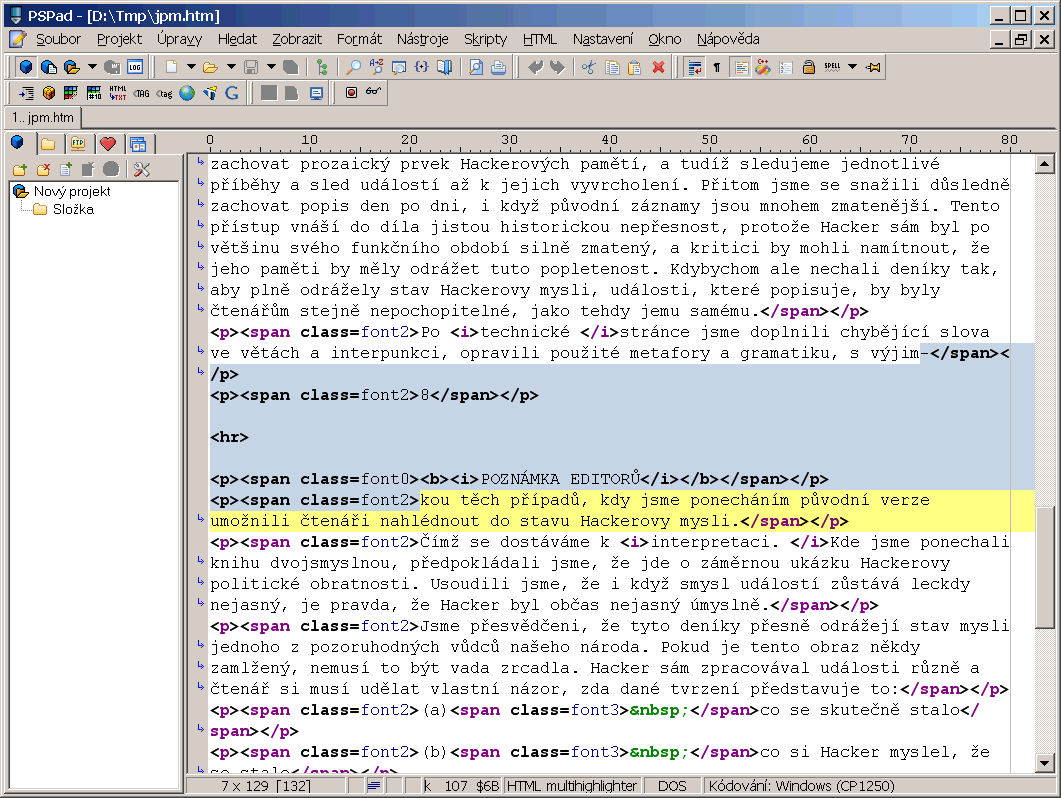
Právě tohle ruční odstraňování je důvod, proč vlastně ve FineReaderu používám nastavení „Použít plnou čáru jako zalomení strany“ – v kódu sice neuvidím „plnou čáru“, jen element <hr>, ale i ten docela dobře zviditelní místa, kde jedna stránka končí a druhá začíná. Při mazání záhlaví se „zadarmo“ zbavím i tohoto prvku – a když ho nepotřebuji, protože kniha záhlaví nemá? Nic jednoduššího, než „najít“ <hr> a nahradit to prázdným řetězcem – na to ani nepotřebuji žádné regulární výrazy, stačí obyčejné nahrazování…
Soubor knihy po tomto kroku: Download.
Prvotní vyznačení kapitol
Vyznačení kapitol dělám ve dvou krocích. Důvod pro to je poměrně prozaický: Kapitoly potřebuji označit už na tomto místě, kdy se poměrně dobře hledají, ale do definitivní podoby je chci převést až později, protože ta koncová podoba nežádoucím způsobem zasahuje do dalších úprav. Vesměs je v této fázi upravuji tak, aby kapitoly byly tvořeny prostým textem, který začíná nějakým nepoužitým symbolem nebo posloupností symbolů; často používám vlnovku ~ nebo zpětný apostrof `, je však nanejvýš vhodné se je napřed pokusit vyhledat, jestli se náhodou v textu nevyskytují.
Samotné nalezení a nahrazení kapitol je velmi odlišné kniha od knihy. Někdy jde použít regulární výrazy, někdy ne; ale i kdyby ne, kapitol zase tak mnoho v knihách nebývá, aby se to nedalo udělat ručně. Naše kniha je zrovna jedním z případů, kdy to regulárním výrazem moc nejde. Kapitoly jím lze celkem snadno vyhledat (nastavte vyhledávání citlivé na velikost písmen [case-sensitive] a dejte hledat <p>[A-Z '.,!?]+)</p>, ale nemůžete se spolehnout na to, že najdete všechny, a poměrně problematicky by se pak nahrazovalo (kromě názvu povídky potřebujeme zpracovat i jméno autora a rok vydání). Já jsem to radši udělal ručně tak, že jsem název kapitoly uvedl znakem `, jméno autora znakem ~ a rok vydání znakem @:
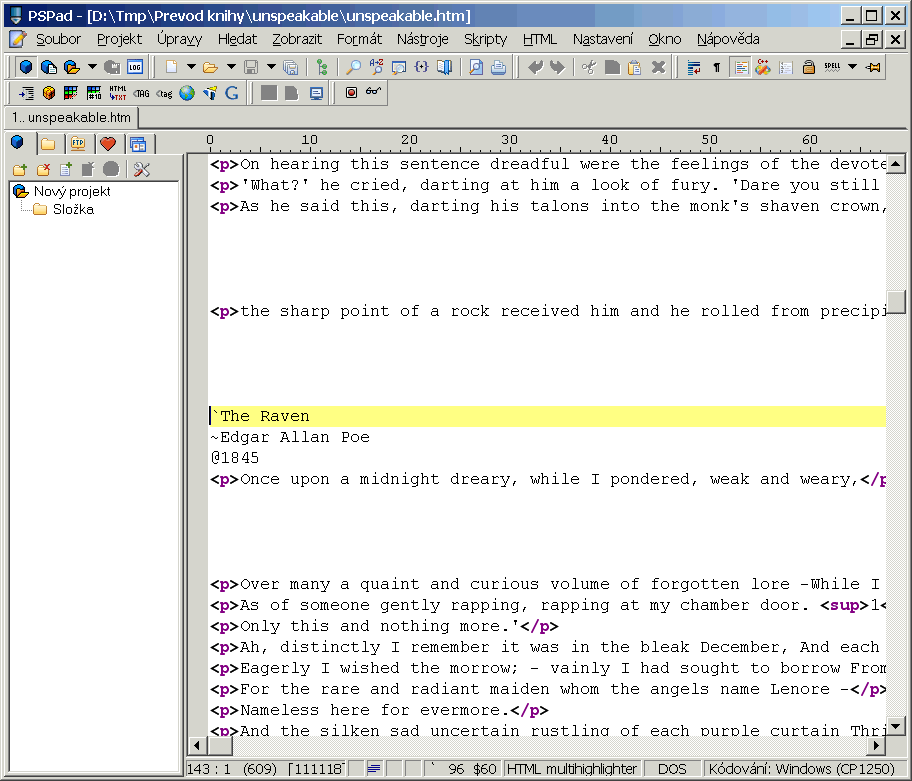
Soubor knihy po tomto kroku: Download.
Odstranění prázdných řádků
Po předchozí opravě zbyla v textu spousta prázdných řádků po smazaných číslech a oddělovačích stránek. Z hlediska HTML to ničemu nevadí, ale není to moc estetické a také by to zesložiťovalo některé další regulární výrazy. Proto v této fázi všechny prázdné řádky odstraním a v případě potřeby je – automaticky – doplním později. Způsobů, jak to udělat, je víc, záleží na tom, jak moc „špinavý“ je váš zdrojový soubor, a co umí váš editor. Osobně používám dvoufázové mazání, kdy napřed zruším všechny mezery na začátku a konci řádků výrazem „Najít“=^\s*(.+?)\s*$ (=najdi všechny řádky, do první závorky dej všechno, co začíná prvním neprázdným znakem a končí posledním neprázdným znakem), „Nahradit“=$1 (=obsah první závorky), a potom použiji víceřádkový regulární výraz (zapnutý příznak dot-all) s „Najít“=[\n\r]+ a „Nahradit“=\n, což nejen odstraní prázdné řádky, ale ještě znaky konce řádku sjednotí na linuxovém standardu (žádný strach, Windowsové programy si s ním také poradí).
Soubor knihy po tomto kroku: Download.
Spojení rozdělených odstavců
Poměrně běžný problém v OCR je ten, že odstavce jsou rozděleny na místech, kde rozděleny být nemají, případně naopak, chybí konec odstavce tam, kde by být měl. Rozdělování odstavců se automaticky dělá špatně (vím jen o jednom dost spolehlivém způsobu, který jde použít až mnohem později), ale spojování se udělat dá. Způsobů je víc, mě se osvědčilo ověřovat první písmeno následujícího odstavce – pokud to je písmeno malé abecedy, skoro určitě jde o pokračování odstavce předcházejícího. Spojování dělám ve dvou fázích – napřed se postarám o rozdělení uvnitř slov, potom mezi slovy. V obou případech potřebuji víceřádkový regulární výraz citlivý na velikost písmen.
Spojení rozdělených slov dělám pomocí „Najít“=-</p>\n<p>([a-záčďěéíňóřšťúůýž]) (pomlčka, konec odstavce, přechod na nový řádek, začátek odstavce, první znak textu je malé písmeno), „Nahradit“=$1 (ze všech předchozích komponent zůstane právě jen to malé písmeno). Spojení rozdělených odstavců pak podobným výrazem „Najít“=</p>\n<p>([a-záčďěéíňóřšťúůýž]), „Nahradit“= $1 (před $1 je mezera, která tak nahradí sekvenci konec odstavce-nový řádek-začátek odstavce).
Soubor knihy po tomto kroku: Download.
Uvozovky
Když už mám spojené odstavce, mohu se pustit do sjednocení uvozovek. Tohle je nesmírně variabilní část úprav, protože uvozovky jsou v každé knize dělané jinak a výrazně se liší i jejich interpretace OCR programem. Protože uvozovkám se chci důkladněji věnovat v samostatném článku, nepustím se zde do žádného rozboru a jen popíšu regulární výrazy použité v mé ukázkové knize. Pohled do zdrojového kódu ukázal, že levé i pravé uvozovky jsou řešeny stejně, symbolem apostrofu. Ještě než jsem se pustil do záměn jsem si ale všiml, že FineReader často vyhodnotil sekvenci 'I chybně jako T (např. řádek 34), což se ale dá celkem snadno detekovat, protože žádné slovo tvořené jen velkým písmenem T neexistuje. Proto jsem napřed provedl náhradu (case-sensitive, tj. citlivou na velikost písmen) „Najít“=\bT\b (=začátek slova, T, konec slova) za „Nahradit“='I. Teprve potom jsem se pustil do samotného přepisování uvozovek, na které jsem použil výraz „Najít“=([> ])'(.*?[^a-z ])'([< ]), „Nahradit“=$1“$2”$3 (bude rozebráno v samostatném článku) a následně „Najít“="(.*?)", „Nahradit“=‘$1’.
Soubor knihy po tomto kroku: Download.
Kurzíva
Zpracovávaná kniha obsahuje kurzívu a je tedy třeba opravit jedno specifikum FineReaderu – tento program s oblibou začíná kurzívu moc brzo (ještě před uvozovkami) a ukončuje ji buď moc brzo (ještě před interpunkčními znaménky) nebo naopak moc pozdě (až za mezerou nebo uvozovkami). Naštěstí se to dá snadno opravit několika regulárními výrazy, které všechny sdílejí stejnou část „Nahradit“=$2$1 (prohodit obsah první a druhé závorky): Příliš brzo začínající kurzíva používá „Najít“=(<i>)(&[lb][ads]quo;) (v první závorce je začátek kurzívy, v druhé skoro všechny možné „rozumné“ otevírací uvozovky). Příliš brzo končící kurzíva má „Najít“=(</i>)([.,;:!?]+) (první závorka je ukončení kurzívy, druhá je sekvence interpunkčních znamének), příliš pozdě končící zase „Najít“=( +|&r[ads]quo;)(</i>) (v první závorce sekvence mezer nebo pravé uvozovky, v druhé ukončení kurzívy). Nic také nebrání tomu, obyčejnými (neregulárními) nahrazovacími operacemi předělat kurzívu (styl) <i> na zvýraznění (strukturální informace) <em>.
Obdobný postup se dá použít i na další tagy, jako je tučné písmo a podobně.
Soubor knihy po tomto kroku: Download.
Dokončení kapitol
Teď už můžu bezpečně dokončit zvýrazňování kapitol. Vzhledem k tomu, že už mám všechny komponenty připravené v sjednoceném formátu, je to jen sekvence jednoduchých regulárních výrazů.
Pro nadpis kapitoly: „Najít“=^`(.+) (řádek začínající zpětným apostrofem, obsahem první závorky bude všechno za apostrofem), „Nahradit“=</div>\n\n<div class="chapter">\n<h2 id="chapter-1">$1</h2> (tento výraz napřed ukončí předchozí kapitolu, pak začne novou a vytvoří její titulek; problém je v tom, že všem kapitolám přiřadí stejné ID chapter-1, takže pak musíte soubor projít a ručně přečíslovat; pokud však používáte FAR a jeho Regular Expressions, můžete místo chapter-1 použít chapter-$R – $R bude nahrazeno pořadovým číslem [počínaje od nuly, takže je dobré na úplný začátek knihy dát „umělou kapitolu“, něco jako `xxx, kterou po zkonvertování smažete])
Pro jméno autora: „Najít“=^~(.+), „Nahradit“=<h3 class="author">$1</h3> (jen jednoduché ostylování).
Pro rok: „Najít“=^@(.+), „Nahradit“=<h3 class="year">$1</h3> (to samé, jen s jiným úvodním znakem a jiným názvem stylu).
Soubor knihy po tomto kroku: Download (v archívu jsou dva soubory – jeden finální, jeden před odstraněním „falešné“ „číslovací“ kapitoly).
Dočištění HTML
V souboru stále ještě zbyla řada tagů, které tam nemají co dělat – mimo jiné je tam dvanáctkrát tučné písmo (které v papírové knize nikde není, jde jen o chybné rozpoznání), dvakrát horní index (místo apostrofu), 13 míst s fonty jinými než zbytek knihy (celá kniha používá jediný font) atd. Dalo by se to odstranit poloautomaticky (zjistit, jaké jsou nadbytečné tagy, a pak je něčím typu „Najít“=</?span.*?>, „Nahradit“= odstranit), ale víc se mi osvědčuje je v nějakém vhodném editoru dohledat a odstranit ručně – jsou to důsledky chybné detekce a je téměř jisté, že poblíž nich budou i další chybová místa, která by při tom hromadném automatickém odstranění zůstala nezměněna. Stejně bych je musel při obsahové korektuře opravit, tak proč to neudělat při technické, kde se mi aspoň snadno hledá…
Tuto část korektury už jsem se rozhodl nedělat – už jsem ji dělal jednou, a ani pro demonstrační účely nemá takovou hodnotu, aby stálo za to podstupovat tu dřinu podruhé. Místo toho vám nabízím svůj prográmek Tags, který umí v souboru najít všechny použité tagy a některá další speciální místa a vypsat je (do konzole, pochopitelně – stejně jako skoro všechny moje prográmky se i tenhle ovládá přes příkazovou řádku) i s počtem výskytů: Tags – nástroj pro čištění HTML knih.
Nezapomeňte také doplnit hlavičku HTML souboru (viz článek o šabloně) a následně využít služeb Validátoru HTML k dohledání zapomenutých strukturních chyb…
Díky moc za návod! Seš borec! Druhým dnem se tu mrcasim s obdobným problémem, avšak až díky tvému návodu, a v kombinaci s jinými nalezenými řešeními, jsem dokázal svůj problém nadobro vyřešit.
Možná je problém ve verzi FARu, ale určitě ne v tom, že to je verze 2 – sám ji používám a RESearch v ní v pohodě funguje. Spíš bude problém v tom, že distribuční archív RESearchu obsahuje čtyři různá DLL a je vhodné, pokud ne nutné, nechat tam jen jedno z nich – to, které odpovídá verzi FARu a jeho bitovosti. Já pro FAR 2/32bit používám RESearchU.dll.
Tak jsem na to prisel = problem je ve verzi FAR Manazera. Vyhnete se verzi 2.
Hmm, tak mi stejne ty makra nefungujou – tedy vypadaji, ze ano, ale zaroven zkorupti cely soubor. Zkousel jsem to spojovani rozdelenych slov. Tak slovo spoji ale zaroven smaze prvni 4 znaky radky. No skoda, vratim se k Notepadu++ a budu to delat rucne.
Nesmíš se dívat na neudržovaný Plugring, ale na diskusní fórum. Konkrétně do sekce „oznámení o nových pluginech“. RESearch.
Mohu se zeptat, kde se ti podarilo sehnat Regular Expression Search and Replace ve verzi 6.2? Na Far Manager pagi maji 5.5 jako jedinou na stahnuti a v ni ty vyrazy nefungujou. Dik.
Záhlaví a patičky určitě mazat – i kdyby se to časem v e-bookách objevilo (třeba v LRF už to je dávno), bude to dělané extra – někde na začátku dokumentu bude řečeno, „na každé stránce nahoře napiš XYZ“. Určitě to nebude tak, že na každé stránce budu chtít znovu a znovu přepisovat dané záhlaví – už jenom proto, že dopředu stejně nevím, kde která stránka začíná…
„Ostatní editace“ se týkala například toho smazání hlavičky HTML dokumentu, prvního označení kapitol nebo závěrečného dočištění. Plus potom samozřejmě celé obsahové korektury. (Akorát jsem trochu kecal, já používám SciTE, ale PSPad mi přišel známější a nechtěl jsem zbytečně uživatele mást použitím obskurního editoru…)
Moc pekny clanek, diky. Poznamka k zahlavim a zapatim : pouzivam FR10, ktery je do html docela uspesne odstrani sam. Dlasi moznosti by bylo udelat z nich paragraf urciteho classu, kteremu se pak v css nastavi {dislay:none;} Co kdyz bude html nekdy v budoucnu umet i hlavicky a paticky.
Jeste otazka – co znamena „pro ostatní editaci pak používám známý PSPad.“ Jakou dalsi editaci – krome popsanych uprav jeste delas?
Dik Jirka