Z papíru do čtečky 5: Technická korektura
Pokračujeme v převodu papírové knihy do elektronické podoby. Po minulém kroku už máme k dispozici HTML soubor s knihou. To ale není všechno. Ten soubor je zatím jen hodně surová verze, která se sice dá v nouzi použít už sama o sobě, ale pokud má e-kniha k něčemu vypadat, je třeba do toho ještě zasáhnout – je třeba sjednotit strukturu dokumentu, upravit obrázky, správně rozmístit poznámky pod čarou, vyřadit nadbytečná záhlaví a patičky apod. Problém je v tom, že tady už končí univerzálně platné pravdy a nastává okamžik, kdy je třeba se s každou knihou vypořádat specificky. Podotýkám, že celý tento návod předpokládá aspoň základní znalost HTML.
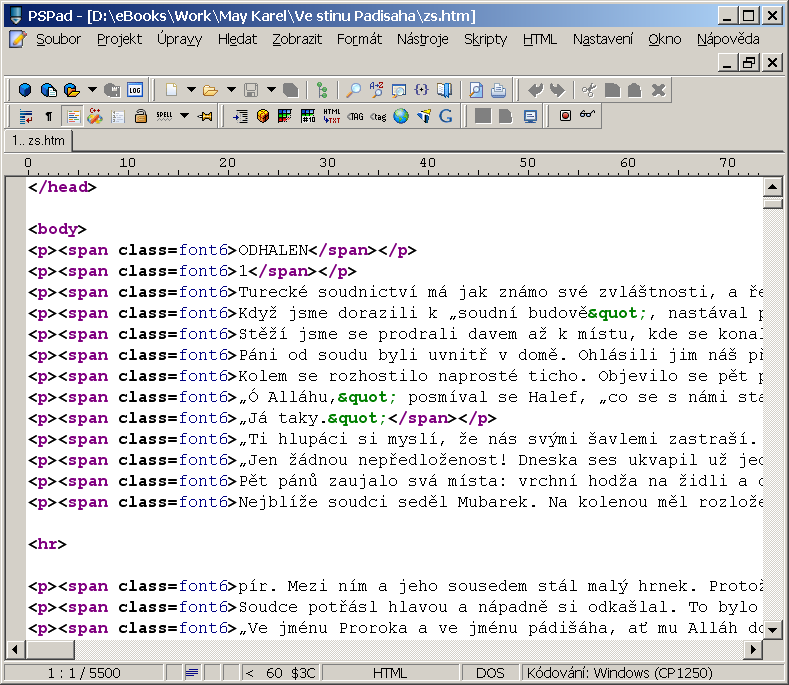
Nahoře vidíte obrázek ještě relativně příznivé situace, kdy má kniha velice jednoduchou strukturu bez záhlaví a patiček a kde FineReader dokázal správně identifikovat čísla (většiny) stránek a vypořádat se s nimi. Přesto je vidět několik nedostatků:
-
Nejsou nijak rozlišeny kapitoly. Nadpisy kapitol jsou stejně jako běžný text vyvedeny v tagu
<p>, zatímco ve finální knize by pro ně byl vhodný nějaký z hlavičkových tagů<h1>až<h6>(já používám<h2>jako nejvyšší „volný“ tag, protože<h1>vyhrazuji pro hlavičku knihy – název, autora apod.). -
Každý odstavec je naprosto zbytečně stylován tagem
<span>, přitom by úplně stačilo nechat odstavce uvnitř obyčejného tagu<p>. Navíc se často stane (tady naštěstí ne), že FineReader zachytí naprosto nepodstatné a lidskému zraku neviditelné změny velikosti písma a každý odstavec nastyluje na mírně odlišný styl. -
Uvozovky jsou nekonzistentní: otvírací uvozovky jsou tvořeny běžnými uvozovkami dole, zatímco zavírací uvozovky jsou řešeny symbolem
"– vhodné by bylo sjednotit to na jeden tvar. -
Jednotlivé stránky jsou oddělené a přerušují i tok odstavců.
U složitěji formátovaných knih přibývá ještě celá řada dalších typických chyb:
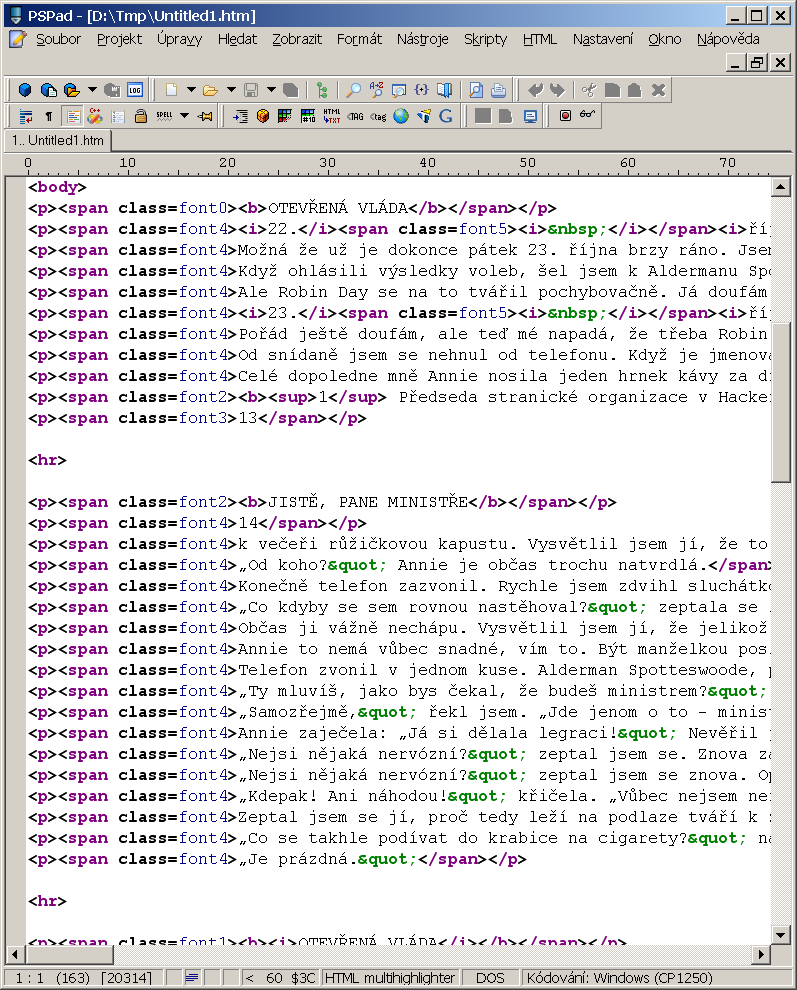
-
Generátor vytváří sice formálně správné, ale nanejvýš podivné konstrukce typu
<i>22.</i><span class=font5><i> </i></span><i>října</i>, které by člověk napsal mnohem jednodušeji jako<i>22. října</i>nebo v tomto konkrétním případě ještě spíš i bez tagu<i>jen jako hlavičku kapitoly nižší úrovně (třeba<h3>). -
Poznámky pod čarou jsou zamíchané do textu, vhodnější je umístit je všechny hromadně na konec dokumentu (nebo možná na konec kapitoly, což je vhodnější pro současnou implementaci formátu EPUB na Sony Readerech) a provázanost řešit běžnými hyperlinkovými odkazy.
-
FineReader si neporadil se záhlavím stránky ani s číslováním stránek, ze kterých udělal normální text.
FineReader dále vytváří celou řadu dalších chyb nebo nedostatků, které na těchto příkladech nejsou vidět:
-
Čas od času nezachytí některý obrázek, nebo naopak zachytí obrázky, které nejsou obrázky ale jen zašpiněné stránky. Po dokončení úprav je třeba projít všechny naskenované stránky, najít obrázky a přesvědčit se, že jsou v zkonvertovaném souboru obsaženy – a že tam nejsou žádné jiné. Obrázky je navíc třeba vhodně upravit – typicky správně oříznout, zredukovat na vhodný počet stupňů šedé barvy a obvykle také znormalizovat (nejtmavější místo převést na sytě černou, nejsvětlejší na jasně bílou a všechno mezi na vhodnou úroveň šedé).
-
Pokud obrázek obsahuje text, program to často úplně zmate a pokusí se i obrázek převést jako text.
-
FineReader sice pozná kurzívu, ale ne vždy správně najde její začátek a konec (často například začne o slovo dřív nebo později, než by měl) a chová se poněkud zvláštně v případě, že uvnitř kurzívy má být nějaký symbol. Typicky také kurzívu skončí až za poslední mezerou a ne před ní.
-
Často je detekováno tučné písmo, když prostě jen tiskárna vyjela nějakou část stránky výrazněji než obvykle.
-
Velký problém jsou konce odstavců, které často nejsou detekovány vůbec.
-
V českém textu se velmi často stane, že nejsou detekovány uvozovky dole ale dvojice čárek, případně jen jedna čárka.
-
Výjimkou nejsou mezery v místech, kde by být neměly (před interpunkčními znaménky, za jinými mezerami atd.).
Chyb je ještě víc, ale tohle jsou ty nejběžnější. Podstatné je, že většinu z nich lze docela dobře detekovat a opravovat „téměř automaticky“ – člověk se musí podívat, jak přesně jsou v té které knize reprezentované, ale potom obvykle lze napsat vhodný regulární výraz, který je dokáže všechny najednou opravit. Je ovšem třeba počítat s tím, že HTML není regulární jazyk a existují v něm konstrukce, které nelze regulárními výrazy popsat. Naštěstí v souborech vytvořených pomocí OCR jsou tyto případy velmi vzácné.
Při praktickém použití také dejte pozor na to, že editory často podporují jen podmnožinu regulárních výrazů nebo si jejich syntaxi poněkud upravují; syntaxe uvedená zde bude ve tvaru, který používá plugin Regular Expression Search and Replace pro FAR Manager, která se velmi blíží té nejobvyklejší, pouze místo mezer píšu v těchto příkladech podtržítko, aby byly vidět; pokud není uvedeno jinak, předpokládají se jednořádkové regulární výrazy bez rozlišování velkých a malých písmen.
(Vzhledem k chování FARovského editoru u FARu ale upozorňuji na to, že předem je třeba v nějakém grafickém textovém editoru převést speciální znaky jako „ na entity „, protože FAR si je jinak přeloží na nejbližší zobrazitelný textový znak.)
| Najít | Nahradit | Efekt |
|---|---|---|
\s+ |
_ |
Nahradí sérii prázdných znaků (mezer, tabulátorů apod.) jednou mezerou. |
<p><span class=fontčíslo fontu>(.*)</span></p> |
<p>$1</p> |
Převede zbytečně stylovaný odstavec na nestylovaný odstavec. |
</i>([^a-z]*)<i> |
$1 |
Odstraní zbytečné konce a začátky kurzívy. Totéž jde po vhodné záměně i použít i na další tagy. |
(symbol1)(symbol2) |
$2$1 |
Prohodí pořadí symbolu 1 a 2. Hodí se to na spoustu věcí, například pro zařazení kurzívy až za otvírací uvozovku (pak je symbol1 = <i> a symbol2 = otvírací uvozovka), pro zařazení konce kurzívy před zavírací uvozovku, pro uzavření kurzívy ještě před mezerou atd. atd. |
(<p>),+ |
$1otvírací uvozovky |
Opraví špatně identifikované uvozovky na začátku vět. |
otvírací uvozovky(.*?)zavírací uvozovky |
nové otvírací uvozovky$1nové zavírací uvozovky |
Převede jeden styl uvozovkování na jiný styl. Specielně se to hodí pro případy, kdy jsou otvírací i zavírací uvozovky dělány jedním znakem. U stylů, kdy je pro otvírací i zavírací uvozovku použit odlišný symbol, není vůbec třeba řešit regulární výrazy a stačí použít dvě normální nahrazení. |
([>_])'(.*?[^a-z_])'([<_]) |
$1nové otvírací uvozovky$2nové zavírací uvozovky$3 |
Tento výraz docela dobře řeší americké knihy, kde jsou uvozovky uvedeny v podobě apostrofu, který ovšem koliduje s apostrofy normálními. Neporadí si se všemi případy, problém dělají třeba slova začínající apostrofem, ale celkově má až překvapivě dobrou úspěšnost. |
zavírací uvozovky\s*otvírací uvozovky |
zavírací uvozovky</p>\n<p>otvírací uvozovky |
Dotváří některé chybějící odstavce (je zvykem, že každá postava má svou přímou řeč v samostatném odstavci). |
\n+<hr>\n+ |
\n |
Toto je víceřádkový výraz, který vyhází všechny ty čáry na rozmezí stránek. Hodí se u knih, kde nejsou záhlaví ani patičky (viz první příklad), kde ty čáry jsou úplně k ničemu. U složitějších knih (druhý příklad) je lepší tento výraz nepoužívat a přechody mezi stránkami udělat ručně – stejně budete muset odstranit hlavičky a číslování stránek a na to jsem žádný dobrý rozumně univerzální regulární výraz nenašel – ručně je to přitom otázka dvou kliknutí a dvou kláves (klik na začátek odstraňovaného textu, podržet SHIFT, klik na konec odstraňovaného textu, DELETE) a vyřeší to všechny tyhle nadbytečné potvory – případně se to dá zkombinovat i se spojováním odstavců. Těch 300 opakování, nebo kolik máte stránek, se už dá vydržet. |
</p>\n+<p>([a-záčďěéíňóřšťúůýž]) |
_$1 |
Tento výraz je také víceřádkový a navíc vyžaduje rozlišení malých a velkých písmen. Pak docela přijatelně spojuje nadbytečně rozdělené odstavce (např. na rozhraní dvou stránek). |
Po provedení těchto úprav je vhodné z dokumentu smazat hlavičky, které tam umístil FineReader, a nahradit je hlavičkami vlastními. Já třeba používám následující:
<?xml version="1.0" encoding="windows-1250"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="content-type" content="text/html; charset=windows-1250" /> <title>Název knihy</title> <meta name="author" content="Autor" /> <link rel="stylesheet" href="Cesta ke společnému stylopisu" type="text/css" /> </head> <body> <div class="header"> <h1 class="title">Název knihy</h1> <h1 class="author">Autor</h1> <h1 class="year">Rok vydání</h1> </div> <div class="toc"> <h2>Obsah</h2> <ol> <li><a href="#chapter-1">Kapitola 1</a></li> <li><a href="#chapter-2">Kapitola 2</a></li> <li><a href="#chapter-3">...</a></li> </ol> </div>
(Ten seznam kapitol se mimochodem dá také získat regulárním výrazem. Řekněme, že kapitoly mám v dokumentu definované jako <h2 id="identifikátor">Název kapitoly</h2>. Pak si nejprve udělám seznam kapitol příkazem type soubor dokumentu | find "<h2" >dočasný soubor, následně v tom nově vytvořeném dočasném souboru provedu nahrazení (hledám) <h2 id="(.*)</h2> za (nahrazuji) __<li><a href="#$1</a></li> a výsledek vložím do dokumentu.)
Ve finále si ještě droboučkým prográmkem Tags nechám vypsat všechny tagy použité v dokumentu a vypořádám se s těmi, které tam mít nechci – typicky všechny <span>, které jsou až na výjimky buď úplně nadbytečné nebo by měly být nahrazeny vhodně označeným zvýrazněním <em class="označení typu">.
Poslední operace v této fázi korektury spočívá v prohnání dokumentu validátorem HTML a opravení všech chyb, které mi nahlásí. Nebylo by to nezbytně nutné, protože prohlížeče i Calibre si s nevalidními dokumenty poradí, ale je to dobrá kontrola, že jsem na nic nezapoměl. A tím je hromadná korektura dokončena a nadchází poslední nutná operace při tvorbě e-booků – korektura vnitřku knihy. Ale o tom zase až příště.
Další díly seriálu:
- Proč to dělat?
- Zařízení
- Plustek OpticBook 3600
- OCR – FineReader 9.0
- Technická korektura
- Obsahová korektura
Dalo docela práci k tomu WordPress přesvědčit…
Nešlo by tu tabulku s regexpy roztáhnout na celou šířku sloupce?
Dekuju, dekuju, dekuju 🙂
R.