V pátém dílu seriálu o regulárních výrazech se podíváme na možnosti práce s kódováním Unicode, které se velmi hodí uživatelům exotických abeced (například české). Za běžných okolností je totiž knihovna PCRE nastavena pro práci s běžným osmibitovým kódováním znaků (co znak, to bajt), a ještě speciálně pro práci s anglickou abecedou. Abecedy ostatní standardním PCRE podporovány nejsou a buď nejsou použitelné vůbec (japonština a další abecedy, které potřebují více než jeden bajt na reprezentaci jednoho znaku) nebo jen s omezeními (např. čeština – v zásadě funguje, ale neexistuje žádná podpora pro skutečnost, že „č“ je „písmeno“ a ne „speciální symbol“). S podporou Unicode lze ale docela dobře pracovat i s neanglickými abecedami.
(more…)
Zatímco předchozí díly seriálu se zabývaly něcím, co bych označil za základní syntaxi regulárních výrazů, víceméně stejnou ve všech implementacích, ve čtvrtém díle se podíváme na konstrukce, které jsou specifické pro PCRE a nedají se použít skoro nikde jinde. To je sice jejich velká nevýhoda, na druhou stranu jde o konstrukce natolik užitečné, že stojí za to je znát. Konečně totiž dojde i na častou otázku, „jak vyhledat řetězec, který neobsahuje zadaný podřetězec?“
(more…)
Třetí díl seriálu o regulárních výrazech bude věnován obyčejným kulatým závorkám ( a ). Ony vlastně ani nejsou zvlášť složité, celá jejich funkce by se snadno dala shrnout do tvou slov „vymezení skupin“ – jenže jde o to, že tímhle jedním mechanismem jde provádět celou řadu zajímavých operací, drtivé většině uživatelů neznámých. Na ty ale dojde až v příštím pokračování, dnes se seznámíme jen se základním použitím závorek, na které v dalším díle navážeme (a konečně v něm dojde na slibovanou často žádanou funkčnost „jak napsat výraz, který nenajde zadané slovo“).
(more…)
V prvním díle série o regulárních výrazech jsem lehce naťukl, co to vlastně ty regulární výrazy jsou a na jaké problémy se musíte připravit, pokud chcete regulární výrazy používat. Také jsem ale říkal, že přes to všechno jsou regexpy nesmírně užitečným nástrojem, který stojí za to umět používat. V dnešním díle už dojde na lámání chleba: pustíme se do základních regulárních výrazů.
(more…)
Pokud trochu sledujete zdrojové kódy mých programů, jistě jste už zjistili, že v nich se železnou pravidelností používám regulární výrazy (regexpy – z „regular expression“). Proč to dělám? Protože regulární výrazy jsou nesmírně užitečným nástrojem pro zpracování textu, který se navíc dá v takřka stejné podobě použít všude možně – nemusíte být zrovna programátor, abyste ocenili sílu regexpů, protože je můžete i bez znalosti programování použít třeba v mnoha textových editorech. A protože mě známé české popisy podle mě vykazují řadu nedostatků, rozhodl jsem se napsat sérii článků uvádějících do úžasného, i když trochu mystického, světa regulárních výrazů. Ke čtení bych je doporučil zejména těm, kdo a) chtějí upravovat moje programy, nebo b) chtějí vytvářet e-booky podle mých návodů.
(more…)
Už delší dobu jsem se nezmiňoval o žádných firmwarech pro čtečky od Sony, ale to neznamená, že by nebylo nic k dispozici – jen nemám dost pokusných morčat :-). Nicméně teď jsem ve spolupráci s Rabolem ověřil, že počeštit novou PRS-650 není žádný problém, a lze očekávat, že zrovna tak nebude problémem PRS-350 (pro otestování kterého jsem nicméně zatím žádnou oběť nesehnal). Takže pokud máte z USA dovezenou PRS-650, chcete do ní dostat češtinu a báli jste se postupovat podle ruských návodů, čtěte dál.
(more…)
Po delší době zdánlivé nečinnosti se vracím k Sony Readeru: narazil jsem totiž na velice zajímavý nový projekt jménem eBook Applications. Co to je? Nic víc a nic míň než alternativní firmware pro Sony Reader PRS-505 a PRS-300. A narozdíl od PRS-Plus v něm nejde „jen“ o úpravy originálního firmware, ale o vytvoření firmware úplně nového – například s podporou řady nových e-bookových formátů. Tedy v podstatě o to, o co se snaží projekt InkPot, který ovšem na čtečky Sony zřejmě už definitivně rezignoval.
(more…)
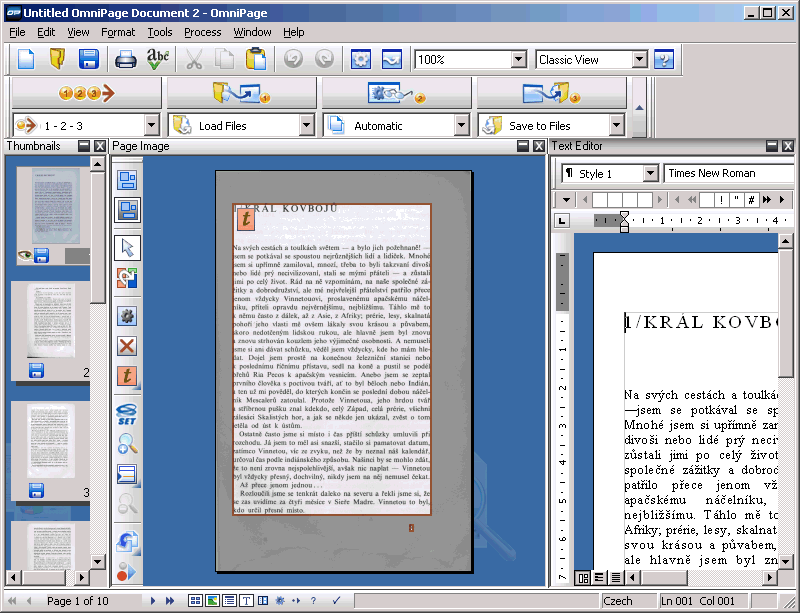
Vracím se ke svému projektu, ve kterém zkouším schopnosti OCR programů. Po FineReaderu 10, který jsem zkoušel minule, přišla řada na OmniPage 17 firmy Nuance.
(more…)
Už delší dobu používám pro zpracování svých knížek do elektronické podoby FineReader 9.0. Jsem s ním v zásadě spokojený – už jsme si na sebe vzájemně zvykli, naučil jsem se jeho výstup upravovat do podoby, která mi vyhovuje, vím, na co si u něj dávat pozor. Proč tedy měnit, co funguje? Protože vývoj jde v tomto oboru dost rychle kupředu a to, co bylo loni skvělé, už letos může být jen průměrné. A protože převod knih do elektronické podoby stále ještě stojí hodně práce, každé zlepšení se počítá. Rozhodl jsem se proto vyzkoušet, jak si stojí aktuální verze OCR programů – jestli by třeba nestálo za úvahu aktualizovat. Jako první jsem vyzkoušel FineReader 10 – jako nástupce dosud používaného programu byl jasným kandidátem…
(more…)
Několik čtenářů mě požádalo, jestli bych nesepsal nějaké povídání o převodu čistě textových e-booků do HTML podoby (viz Šablona pro HTML knihu). Na rovinu říkám, že s tím mnoho zkušeností nemám, protože v drtivé většině případů, kdy jsem se o to pokoušel, se ukázalo, že to nestojí za tu námahu – knihy v plaintextu se často vyznačují skutečně příšerným OCR, a i když je OCR v pořádku, pořád tu je problém, že prostý text prostě nenese všechny potřebné informace (např. o kurzívě, která se v knihách vyskytuje až nečekaně často). Ale čas od času se stane, že opravdu není jiná cesta než vyjít z prostého textu a ten nějak zpracovat. Moje postupy pro tento případ jsou uvedeny ve článku – a stejné postupy lze použít i pro nejběžnější variantu formátu PDB, který je vlastně jen komprimovaným prostým textem.
(more…)