Pokud máte strach upravit si čtečku k obrazu svému, tak mám dobrou zprávu: Šikovný ruský hacker Rupor nalezl způsob, jak zazálohovat komplet celý firmware PRS-T1 do souboru a v případě potřeby ho zase obnovit. Oba způsoby jsem vyzkoušel (zálohu plánovaně, obnovení neplánovaně) a funguje to. Originální návod v ruštině je zde, Google Translate to celkem přijatelně přeloží.
(more…)
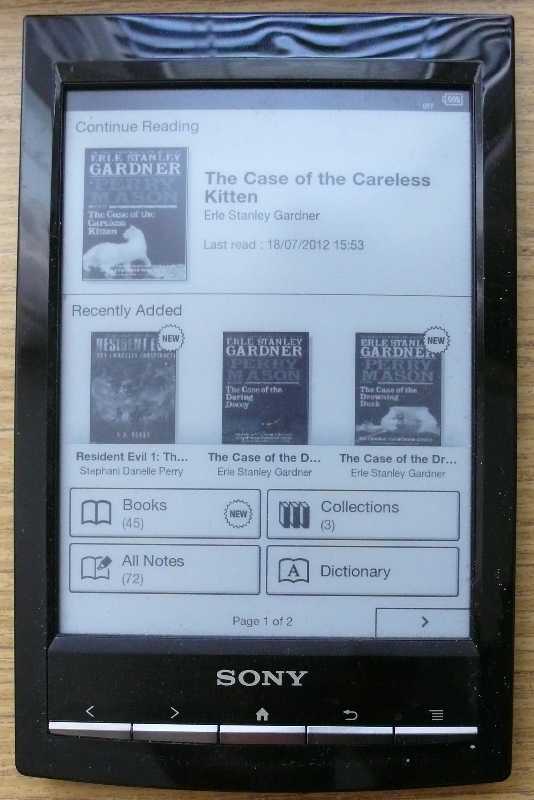
Před čtvrt rokem jsem tu zveřejnil své první dojmy ze čtečky Sony PRS-T1. Nyní už na ní mám přečteno dost knih na to, abych mohl některé závěry opravit nebo doplnit. Takže pokud stále ještě nemáte svoji čtečku a váháte i nad PRS-T1, třeba zde najdete odpovědi na své otázky. Pokud už ji máte, pokusím se popsat řešení problémů, o kterých vím.
(more…)
Je to něco přes dva roky, co jsem zde poprvé uvedl aplikaci ColBuild určenou pro automatizovatelné vytváření sbírek na čtečce Sony Reader PRS-505. Od té doby uběhla spousta času, častým používáním jsem odhalil slabá místa programu a nakonec v souvislosti s nákupem čtečky Sony Reader PRS-T1 zjistil, že celou aplikaci je třeba zásadně předělat, pokud ji chci i nadále používat. A tak jsem tady.
(more…)
Před dávnými věky, kdy se u nás e-inkové čtečky ještě skoro nevyskytovaly, jsem se tu rozepisoval o Sony Reader PRS-505. Nyní, o tři roky později, jsem se rozhodl koupit čtečku novou – ani ne tak kvůli tomu, že by PRS-505 nestačila, ale proto, že se konečně rozšířilo dotykové ovládání, od kterého jsem si sliboval snadnější opravování chyb v e-knihách. Volba padla na PRS-T1, opět od Sony.
(more…)
Pokud už jste se zabývali tím, jak si na čtečkách Sony*) efektivně číst sérii Úžasná Zeměplocha od Terry Pratchetta, možná už jste si všimli, že je docela problém přinutit Smrtě, aby v e-knize mluvil kapitálkami, protože čtečka ani v jednom z podporovaných formátů neumí kapitálky zobrazit.
*) A nejen tam. Stejný problém mají přinejmenším všechny čtečky, které pro zobrazení formátu EPUB používají Adobe Digital Editions, což všechny, které umějí chráněný EPUB.
(more…)
No vida. Neuplynul ani měsíc od doby, kdy jsem tu psal návod na zprovoznění českých znaků ve čtečce Sony PRS-T1 pomocí úpravy jednotlivých knih, a už tu máme postup, jak dostat češtinu do všech knih najednou, aniž by se musely potupně upravovat. Příslušný hack vytvořil uživatel Morkl z diskusního fóra MobileRead (příslušné vlákno).
(more…)
U příležitosti vánoc jsem pořídil novou dotykovou čtečku Sony PRS-T1, která je úplně jiná než ostatní modely, takže po delší době klidu mám důvod hledat řešení nejrůznějších problémů (u čteček předchozích jsem tu motivaci neměl, protože buď nebylo co řešit, nebo to řešení neexistovalo. U T1 se ale opět najde řada zajímavých problémků k vyřešení. První z nich je čeština.
(more…)
Druhý z dlouho používaných ale nedokončených nástrojů se zabývá uvozovkami. Problematice uvozovek v HTML knihách už jsem se kdysi zabýval, ovšem musel jsem se spokojit se závěrem, že ideální řešení neexistuje. Prográmek Quotes je mým pokusem o to, jak nejlepší dostupné řešení aspoň trochu dostat do použitelného stavu.
(more…)
Už dost dlouho jsem tu nepsal nic o elektronických knihách. Důvod je prozaický: Postupně se mi podařilo dosáhnout stavu, kdy jsou všechny problémy vyřešeny nebo jsem aspoň dospěl k závěru, že vyřešit nejdou, a tudíž nemám důvod nic dalšího hledat. Nicméně: mám tu několik programů, které jsem kdysi dávno napsal s myšlenkou, že je vyzkouším v praxi, opravím všechny významné chyby a pak je pustím ven. Od té doby uplynuly skoro dva roky a já ty prográmky skoro každý den spokojeně používám, aniž bych na jejich kód sáhl. První z nich, který už jsem kdysi „bokem“ uvedl v jednom článku, ale dosud neměl samostatnou stránku, je Tags.
(more…)
Prvních pět dílů seriálu o regulárních výrazech se zabývalo tím, jak tyto výrazy zformulovat – jejich stavebními bloky a tím, jak je skládat dohromady. Neřešili jsme ale otázku, co s regulárním výrazem, když už je napsaný. Na to odpoví až dnešní díl, ve kterém si povíme něco o vyhledávání, nahrazování a dalších operacích s regulárními výrazy, včetně několika nových zápisů, které se pro tyto účely dají vhodně využít.
(more…)